Harvestman control of Out-of-domain links listed
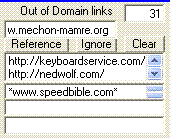
Count of current entries in the Spider's list of out-bound links (plus References links)
"Add to an Ignore list" textbox
- "Reference" button
- Copies a partial URL from the textbox into the references list, adds an asterisk before and after.
- Adds the resulting partial URL to the Spider's internal ignore list.
- "Ignore" button
- Copies a partial URL from the textbox into the ignore list, adds an asterisk before and after.
- Adds the resulting partial URL to the Spider's internal ignore list.
- "Clear" button
- Clears the reference list
- Clears the ignore list
- Clears the Spider's internal ignore list.
Copy of Spider's list of out-bound links
The References listbox
URLs in the References listbox are ignored by the Spider but included in Harvestman's report.
The Ignore listbox
URLs in the Ignore list are totaly ignored
"Break on match" textbox
Locate a bad link
So, you crawl your site, and you have sixty pages, and one of those pages is trying to call
can2can.biz instead of can2can.biz/ (the domain index page is detected as out of domain!); out of sixty pages, how to find it?? Type '*can2can.biz' into the Break on Match
textbox, and re-crawl your site. Harvestman 'Crawl all' will stop crawling as soon as the bad URL is added to the list,
with the URL and title up there in the control area.



Last edited =